My Google Summer of Code project was done under the Ste||ar Group organisation. I was working on HPX, a C++ Standard Library for Concurrency and Parallelism. It implements all of the corresponding facilities as defined by the C++ Standard.
Project Description
Execution policies in C++ refer to a feature introduced in the C++17 standard that provides a standardized way to control the parallelism and concurrency of certain algorithms in the Standard Template Library (STL). These policies allow you to specify how certain algorithms should execute, either sequentially, in parallel or in an unsequenced fashion.
-
std::execution::seq : This policy specifies sequential execution. Algorithms executed with this policy will run serially in the order they appear, with no parallelism or concurrency.
-
std::execution::par : This policy allows algorithms to execute in parallel if deemed beneficial by the implementation. The exact level of parallelism is determined by the compiler and runtime, taking into account factors like the number of available processor cores and the size of the input data.
-
std::execution::par_unseq: This policy enables both parallel and vectorized execution. It is suitable for algorithms where the data can be processed in parallel and vectorized operations can be applied to individual elements. This policy aims to exploit SIMD (Single Instruction, Multiple Data) capabilities for performance gains.
-
std::execution::unseq (since C++20) : This policy enables vectorized execution. It is suitable for algorithms where vectorized operations can be applied to elements. This policy aims to exploit SIMD (Single Instruction, Multiple Data) capabilities for performance gains.
The project focused on implementing vectorization using openMP to optimise std::execution::unseq and std::execution::par_unseq execution
Project Report
NOTE: Mesurements were made using the Medusa node of the Rostam cluster.
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 1
Core(s) per socket: 20
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
Stepping: 4
CPU MHz: 3700.000
CPU max MHz: 3700.0000
CPU min MHz: 1000.0000
BogoMIPS: 4800.00
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 28160K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd mba ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke md_clear flush_l1d arch_capabilities
std::uninitialzed_*
Algorithms like std::uninitialzed_copy, std::uninitialzed_move, etc., can be optimised for trivial types if the container stores the data contiguously in memory. Instead of using a usual for loop to copy each element individually, we can use std::memcopy or std::memove. This gives significant performance improvements.
The following graph shows performance improvements on std::memcpy instead of simple sequential for loop.
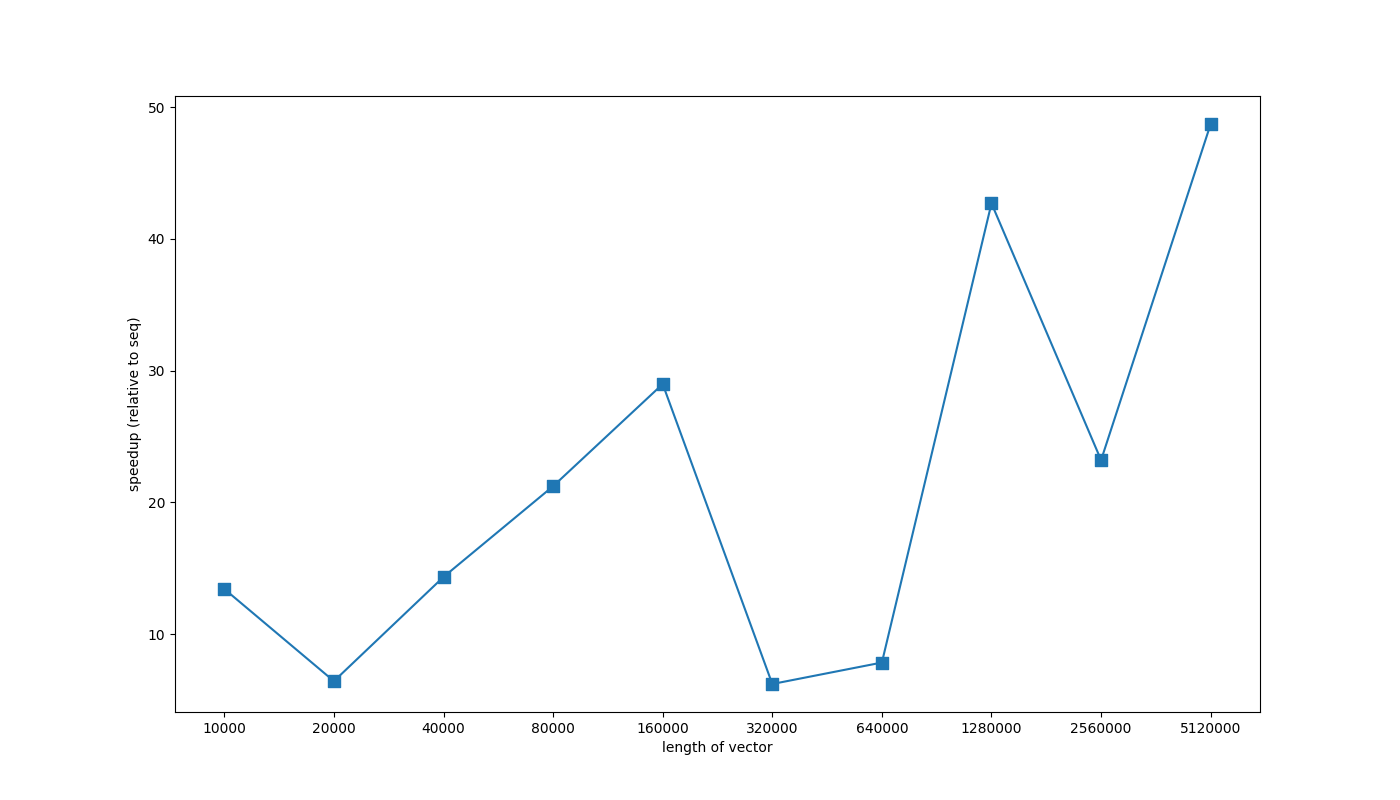
Vectorizating loops with conditional break
Loops with conditional breaks can be vectorized by using simd reduction on a vector lane and breaking out if the reduction returns true
This allows us to vectorize STL algorithms like remove, find …
i=0
while(i<= n-LANE_SIZE){
FlagTy flag = 0;
/*
check if any of the elements in a chunk
evaluate predicate to 1.
Flag set to true if that's the case
*/
VECTOR_REDUCTION (|)
for(j=i; j < i+LANE_SIZE; j++)
{
FlagTy t = pred(jth element);
lane[j-1] = t;
flag |= t;
}
/*
If flag is set to true,
check which element in the chunk
evaluates to true
*/
if(flag)
{
j=0;
for(;j<LANE_SIZE;j++){
if(pred(lane[j]))
break;
}
return (i+j);
}
i+=LANE_SIZE
}
// evaluate the last couple elements
for(; i < n; j++)
{
if(pred(jth element))
return j;
}
return j;
LANE_SIZE is \(\frac {\mathrm{size-of-simd-register}}{\mathrm{size-of-datatype}}\) = number of elements which can fit in one simd register
Performance Improvements observed are as follows:
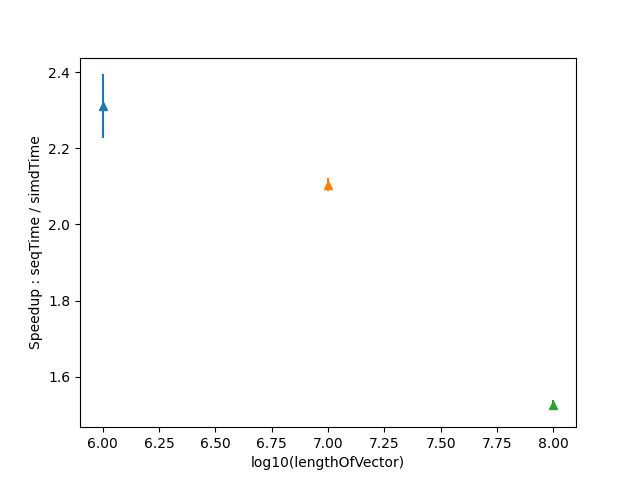
Container is a vector where loop breaks at the \(\frac{\mathrm{len}}{2}\) element
Errorbars show the variance of meaesured data
Performance was measured against a simple for loop
for(i=0; i<n; i++)
{
if(pred(ith element))
break;
}
We had observed that vectorization of the following loop is quite hard, often small changes such as changing Datatype of flag variable can lead to vectorization breaking for certain compilers and architectures.
Untill GCC 9, vectorization is enabled only in case of int32_t not for int8_t
in case of Clang it is the opposite, vectorization is enabled for only int8_t until Clang 14. Godbolt
Testing performance on GCC 11 (vectorizes in both cases) has shown int32_t to be around 40% faster then int8_t (90 mus vs 53mus)
If vectorization does not occur this algorithm in 2 times slower then using a simple for loop, hence performance regression tests were added to make sure no breaking changes would be made in the future.